
Algoritmos basados en animales (II)

{kind=link}
Imaginemos la siguiente situación: los administradores de una red social (puedes pensar en Facebook, por ejemplo) pretenden buscar un subconjunto de sus usuarios al que todo el resto esté conectado directamente (como amigos, seguidores, etc). El propósito es que, una vez conocido este subconjunto, si todos sus miembros enviasen el mismo mensaje éste llegaría a todos los usuarios de la red. Obviamente se busca el subconjunto con el menor número de miembros. Tomemos como ejemplo la siguiente red de pequeño tamaño, en la que cada nodo es un miembro de la red social y las aristas unen miembros conectados entre sí por una relación directa de «amistad».

Fijémonos en los cinco nodos que están marcados en rojo en la siguiente figura, que son una posible solución al problema planteado: cualquiera de los nodos en gris está conectado a uno rojo, y no hay ningún nodo rojo que pueda eliminarse sin que alguno de los nodos de la red se quede sin recibir información directa. Dos nodos rojos tampoco están conectados entre sí.
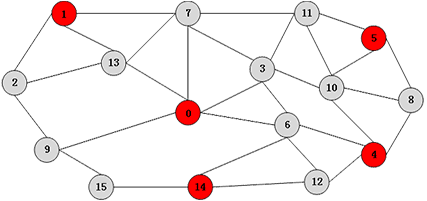
A este conjunto de nodos en un grafo que cumple la propiedad de que no están conectados entre sí, y el resto está conectado al menos a uno de ellos se le denomina conjunto independiente maximal (CIM).
El problema del cálculo del CIM es importante, además de en análisis de redes sociales, en redes de sensores inalámbricos. En estas redes algunos de los sensores son los responsables de recoger los datos de los sensores vecinos y transmitirlos a la central. Esta tarea consume mucha energía, por lo que conviene cambiar con frecuencia qué detectores van a realizar este trabajo, y al hacerlo hay que elegir un subconjunto al que estén conectados el resto de sensores. Ese es precisamente el CIM de la red.
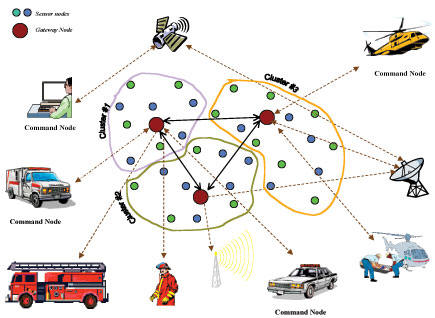
Existen varios algoritmos que permiten calcular el CIM de un grafo, pero la mayoría necesitan conocer la topología del mismo, es decir, saber previamente qué nodos están conectados. Pero hay ocasiones en que esto no puede saberse. Esto ocurre por ejemplo con redes inalámbricas de sensores ambientales o en el control de grupos de robots, donde los movimientos de los sensores varían las posiciones y por tanto las relaciones de vecindad entre nodos. La solución a este problema la podemos encontrar en el desarrollo del sistema nervioso de las moscas.
Pelos de mosca
La mosca de la fruta (Drosophila Melanogaster) tiene en la superficie de su cuerpo un conjunto de pelos que actúan a modo de sensores mecánicos detectores de movimiento. Algunos de estos pelos más pequeños, denominados microsetas, se desarrollan a partir de un grupo de neuronas que son precursores de órganos sensoriales (POS).
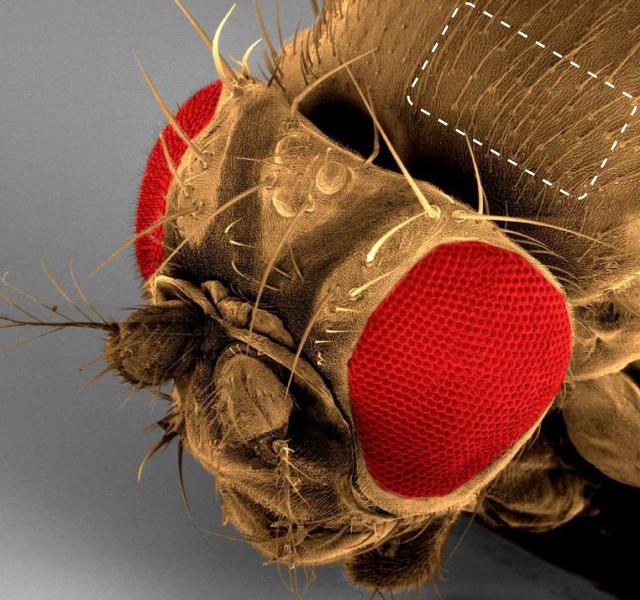
Las células nerviosas que van a desarrollar estos pelos sensoriales se seleccionan durante la fase larvaria de la mosca dentro de grupos de 20-30 células, y la elección se realiza de forma que estos órganos sensoriales estén conectados a otras neuronas pero no directamente entre sí. Al hacer esta elección de neuronas, en la mosca se está resolviendo el problema del CIM. Y de una forma más sencilla y eficiente que algunos de los algoritmos clásicos para resolverlo.

¿Cómo se consigue este resultado? Parece ser que, en principio, todas las células tienen la capacidad de convertirse en pelos sensoriales. Así que algunas de ellas, por mero azar, se «proponen» como POS. Al hacerlo expresan altos niveles de la proteína transmembranal Delta, que se une a los receptores Notch de las células vecinas, inhibiendo la conversión de estas a POS. Este proceso continúa hasta que todas las células son o bien POS o bien están unidas a uno.

Si alguna vez has jugado al buscaminas entenderás mejor este ejemplo con la siguiente figura. Inicialmente podemos seleccionar cualquier casilla del «juego» (en gris). Cuando elegimos como POS una de las células aleatoriamente (en azul) las de su alrededor quedan marcadas (en rojo), porque lo que ya no pueden elegirse en el siguiente paso.
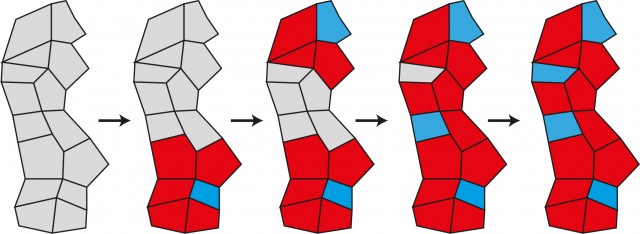
Basándose en esta estrategia, un grupo de investigadores desarrolló un algoritmo para el cálculo del CIM que demostró ser más eficiente que otros algoritmos clásicos y no requería información del grafo, como el número de conexiones de cada nodo. Esto lo hace aplicable a problemas en los que la topología del grafo es variable, como los citados anteriormente de sensores medioambientales o grupos de robots.
Más información
- Yehuda Afek, Noga Alon, Omer Barad, Eran Hornstein, Naama Barkai, and Ziv Bar-Joseph. A Biological Solution to a Fundamental Distributed Computing Problem. Science, 2011; 331 (6014): 183-185 DOI: 10.1126/science.1193210
Soy doctor en ciencias químicas, e inicié mi investigación y doctorado en el campo de la química cuántica. Actualmente soy profesor titular de informática en la Universitat Jaume I de Castellón y colaboro como bioinformático con el grupo «Biología de retrotransposones» del centro de genómica y oncología GENYO de Granada. Mi investigación se centra en el estudio de los elementos genéticos móviles y microARN, así como su influencia en tumores y en enfermedades concretas como el síndrome de deleción 22q11.