

Los datos tienen la mala costumbre de cambiar. Reaccionan a cambios políticos, de opinión, de gustos, de necesidades, … y cómo no también ante una pandemia que impacta de manera global en todos los sectores. La IA se alimenta de estos datos, y debe adoptar mecanismos de detección y adaptación al cambio para cumplir su objetivo…

Imagen original de Pixabay bajo licencia Simplified Pixabay
Los datos tienen la mala costumbre de cambiar. Reaccionan a cambios políticos, de opinión, de gustos, de necesidades, … y cómo no también ante una pandemia que impacta de manera global en todos los sectores. La IA se alimenta de estos datos, y debe adoptar mecanismos de detección y adaptación al cambio para cumplir su objetivo de forma satisfactoria.
Basado en hechos reales …
18 de Febrero de 2020, 8:00 am. Un científico de datos de una gran compañía se percata de que los modelos de recomendación en los que se basa la Inteligencia Artificial (IA) de su departamento llevan 2 días con un rendimiento por debajo de lo esperado. Esto ha repercutido negativamente en las ventas, y por tanto en las cifras de la compañía. Mientras busca el cuadro de mandos en tiempo real para encontrar el origen del problema, piensa:
“… no puede ser, reentrené los modelos a primeros de año con los datos y tendencias más recientes … Espera!, eso del “coronavirus” lleva ya un tiempo generando un interés creciente, pero no puede ser solo la causa del problema … tiene que ser un problema técnico …”
Días más tarde, después de consultar con un compañero, el científico de datos acaba reentrenando los modelos de recomendación manualmente, algo que volverá a hacer varias veces durante las semanas siguientes. En su interior surge un debate:
“… esto no puede ser, no podemos estar pendientes de estos cambios repentinos para reentrenar los modelos, siempre reaccionamos tarde y mal.”

Imagen original del Spring 2015 Community Data Science Workshops de la Universidad de Washington con licencia Creative Commons Attribution-Share Alike 2.0 Generic.
Esta es la situación que han vivido muchas compañías en los últimos meses; queda muy bien reflejada en el reciente artículo de MIT Technology Review [1]: “La IA, incapaz de predecir nuestros súbitos cambios de comportamiento”. Predecir no, pero sí capaz de detectar el cambio y adaptarse rápidamente.
Los datos tienen la mala costumbre de cambiar, de no quedarse quietos, estacionarios, y lo hacen por diversos motivos: cambios en la opinión del cliente, repentinos o graduales cambios en las preferencias de compra, nuevas necesidades con el nacimiento de un nuevo miembro en la familia, … etc. El Covid-19 ha sido un motivo de cambio global a todos los niveles, y será un ejemplo de estudio a partir de ahora. La IA, por muy “inteligente” que nos parezca, no queda excluida de la lista de afectados, y en este artículo veremos porqué.
El Covid-19: detonante del cambio
Si observamos las tendencias de búsqueda de la primera semana del año 2020, nos encontramos con esta lista de temas ordenados por el aumento de frecuencia de búsqueda:
Irán, Enero, Cine bélico, Australia, Guerra, Fuego, Trabajo, Escuela, Estados Unidos, Avión.
No deja de ser una lista de tendencias normal, guiada por las noticias y hechos de ese momento. Pero a mediados de Enero de 2020, algo empezó a pasar, algo que hizo que nuevos términos de búsqueda y tendencias se empezaran a colar en los primeros puestos. Y esto es lo que ha venido pasando hasta hoy. En 2020, estas han sido las tendencias de búsqueda (hasta el 23 de Mayo) más importantes en el mundo y que más bruscamente se han colado en la lista:
Coronavirus, Covid, Virus, Máscara, Google Classroom, Cheque, Whatsapp, Síntoma, Acciones, Italia, Muerte, China, Clima, Precio accionariado, Netflix, Mundo, Receta de cocina, …

Interés suscitado en todo el mundo por el término «coronavirus» en 2020 según Google Trends (hasta el 23 de Mayo).
Esta lista ha ido evolucionando desde la primera quincena de 2020, influenciada por el creciente interés en el término “coronavirus” (ver Figura 1). Los modelos de predicción se han estado volviendo locos intentando adaptarse a la “nueva normalidad” del momento. En muchos casos esta adaptación se ha llevado a cabo de forma manual, con el desgaste y uso de recursos que conlleva. Sólo algunas compañías disponían de sistemas relativamente autónomos y robustos. Su secreto: “machine learning for streaming data” [2]. Secreto que orbita entre el aprendizaje incremental llevado a cabo en tiempo real [3], y las técnicas para mitigar el efecto denominado “concept drift” [4,5]. A continuación, veremos de qué se trata.
El aprendizaje incremental
La IA tradicional, entendida como aquella que se lleva a cabo de forma “batch”, no tiene en general restricciones de tiempo ni almacenamiento. Accede a grandes volúmenes de datos y dispone del tiempo que sea necesario para entrenarse y aprender de ellos. Se beneficia del hecho de que toda la información está disponible y accesible. Los costes de almacenar ese gran volumen de información, y de procesarlo, son de alguna manera asumibles. Pero llega un momento en el que dejan de serlo. Estamos inmersos en una realidad en la que nuestros procesos y aplicaciones se nutren de información en tiempo real, y a los que se le exigen respuestas cuasi inmediatas. Así que la cantidad de información crece de forma exponencial, y ya no toda ella es digna de ser almacenada. La IA ya no tiene tiempo ilimitado para entrenarse y dar una respuesta, se le exige inmediatez. Surge la IA “online”, el “stream learning”. Y como base de todo se encuentra el aprendizaje incremental en tiempo real (ver Figura 2), donde el entrenamiento de la IA se va produciendo a medida que aparece un nuevo dato, no se espera a tener todos los datos para hacer el entrenamiento. Después de usar cada dato para entrenar, éste se descarta, no se almacena. Con esto se consigue el entrenamiento de la IA en tiempos mínimos y no tener que almacenar costosos volúmenes de información. Estos ingredientes han hecho que el “stream learning” haya atraído la atención del paradigma Big Data [6] desde hace ya un tiempo.

Ejemplo de aprendizaje incremental donde un modelo ‘hi’ va siendo evaluado (‘Predict’) y entrenado (‘Train’) de manera online usando el dato (xi,yi) de cada instante de tiempo ‘ti’. Figura tomada de [4].
El cambio (“concept drift”)
En este caso no estamos hablando de un suceso esporádico (outlier), en el que al cabo de poco todo vuelve a la normalidad (ver Figura 3).

Muestra de datos con outliers en x=160 y x=220. Creative Commons 3.0
Hablamos de un suceso repentino, gradual, incremental o recurrente (ver Figura 4) que ocurre en un instante determinado (o durante un tiempo limitado), y provoca un cambio en los datos (habitualmente en su distribución) de ahí en adelante (concept drift).

Tipos de drift. Figura tomada de [4].
La adaptación: automática y en tiempo real

Imagen original de pxhere.com con licencia CC0 Public Domain.
El cambio (drift) hace que los modelos entrenados hasta el momento queden obsoletos, y sea necesaria una adaptación de estos a las nuevas condiciones, o de lo contrario su desempeño empezará a empeorar y resultarán inútiles (ver Figura 5).
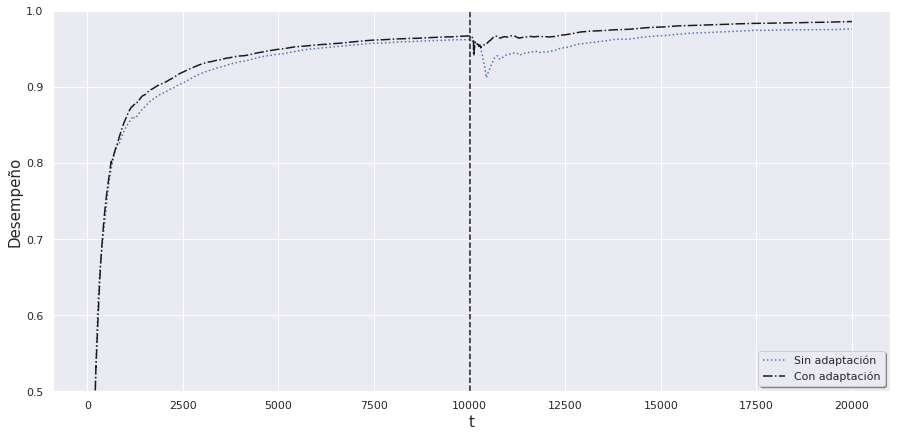
Ejemplo de cómo en t=10.000 se produce un drift de forma repentina, y de cómo un modelo sin adaptación empeora su desempeño (‘accuracy’) mientras que uno adaptado en el instante t=10.100 mantiene el suyo.
A la hora de mantener adaptados los modelos, se pueden seguir 2 estrategias: una pasiva y otra activa.
- En la pasiva, los modelos siempre están actualizados con la nueva información que va llegando a lo largo del tiempo. No importa si se producen cambios o no, puesto que se asume que los va a haber, y por tanto se ponen al día continuamente de forma automática. Esta estrategia es recomendable cuando el cambio (drift) se produce de forma gradual. Es una estrategia que consume más recursos puesto que los modelos están todo el rato actualizándose.
- En la estrategia activa, los modelos solo se actualizan cuando un cambio es detectado, y para esto se necesita un detector de drift. Esta estrategia es recomendable cuando el drift se produce de forma súbita o abrupta. Tienen la ventaja de que sólo se actualizan los modelos después de que haya ocurrido este cambio, y por tanto no se consumen tantos recursos como en la estrategia pasiva. En contra nos encontramos la posibilidad de que el detector de drift cometa falsos positivos, y nos obligue a actualizar los modelos sin que sea necesario, con el consiguiente problema de desempeño.
Esta no es la única decisión que se deberá tomar a la hora de incorporar mecanismos de adaptación. Ante un cambio brusco, puede que sea fácil, y baste con re-entrenar de nuevo los modelos con la información más reciente. Pero con el resto de los cambios (graduales, incrementales, recurrentes) esto no vale. Mientras ocurre el cambio, parte del entrenamiento pasado de los modelos sigue siendo válido durante un tiempo, hasta que el drift se consolide y el nuevo concepto prevalezca. Es aquí donde habrá que decidir qué parte del entrenamiento se mantiene o se descarta (“olvida”). Esto es lo que comúnmente se conoce como “forgetting mechanism”.
Conclusiones
Múltiples aplicaciones y sectores son los que se ven afectados cada día por efecto del concept drift [7]: predicción de demanda, detección de fraude, sistemas de recomendación, intención de compra o predicción de necesidades, control de calidad, predicción de abandono escolar, e-learning, monitorización industrial, e-health, … etc. El “machine learning for streaming data” en presencia de “concept drift” es uno de los campos de estudio más relevantes de la IA de los últimos tiempos debido a su impacto en aplicaciones del mundo real. Atrae cada año a muchos investigadores y empresas, y es fácil encontrarlo en las conferencias de IA más importantes del mundo.
La incorporación de mecanismos adecuados para mantener actualizados los modelos predictivos resulta primordial a la hora de tener IAs robustas al cambio.
Este artículo nos lo envía Jesús (Txus) López Lobo. Licenciado en Ingeniería Informática por la Universidad de Deusto, Máster en Inteligencia Artificial Avanzada por la UNED, y doctor internacional en Tecnologías de la Información y Comunicaciones en Redes Móviles por la UPV/EHU. Trabaja como Científico de Datos e Investigador en Inteligencia Artificial en TECNALIA. También hace divulgación de sus artículos científicos en su blog de Medium: https://medium.com/@txuslopezlobo y en su perfil de Linkedin: http://www.linkedin.com/in/txuslopez
Referencias científicas y más información:
[2] Gomes, H. M., Read, J., Bifet, A., Barddal, J. P., & Gama, J. (2019). Machine learning for streaming data: state of the art, challenges, and opportunities. ACM SIGKDD Explorations Newsletter, 21(2), 6–22.
[3] Losing, V., Hammer, B., & Wersing, H. (2018). Incremental on-line learning: A review and comparison of state of the art algorithms. Neurocomputing, 275, 1261–1274.
[4] Lu, J., Liu, A., Dong, F., Gu, F., Gama, J., & Zhang, G. (2018). Learning under concept drift: A review. IEEE Transactions on Knowledge and Data Engineering, 31(12), 2346–2363.
[5] https://www.kdnuggets.com/2019/12/ravages-concept-drift-stream-learning-applications.html
[6] Zhou, Z. H., Chawla, N. V., Jin, Y., & Williams, G. J. (2014). Big data opportunities and challenges: Discussions from data analytics perspectives [discussion forum]. IEEE Computational intelligence magazine, 9(4), 62–74.
[7] Žliobaitė, I., Pechenizkiy, M., & Gama, J. (2016). An overview of concept drift applications. In Big data analysis: new algorithms for a new society (pp. 91–114). Springer, Cham.





